HashMap对于每一个开发者来说再熟悉不过了,本文就来讲讲它究竟是如何实现的。最开始我并不打算直接对着源码来说这些,从生活中具体事情来说原理,可以让人印象更深刻,也更容易理解!
生活例子
发现问题
生活中你是一个热爱看书的人,所以私底下藏有很多书籍,像《白夜行》、《三体》等,刚开始你都是把书随意放在桌子上,随着时间增长,你的书也越来越多。慢慢的书越来越多,由于书都是无规则的放在桌子上,想快速找到需要的那本书越来越困难。
解决问题
为了快速找到我需要的书籍,我可以把桌子分为N个区域,每个区域用A、B、C这样的字母来标记,然后把书名第一个字的首字母按这个区域标记来规则的摆放(如:安徒生童话=》A,白夜行=》B),当我要找书的时候,可以直接根据名字就能快速的定位到书在哪个区域,找到区域后再找到想要的那本书,速度大大提升了。效果图如下
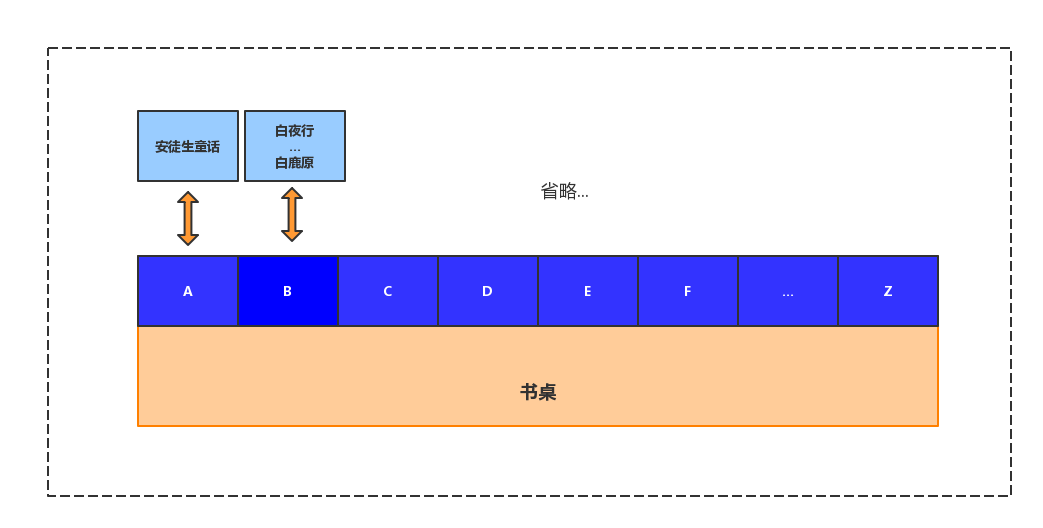
书本《安徒生童话》的首字母为A,因此这本书被你放到了A标记的区域,而《白夜行》和《白鹿原》的首字母都是B,所以它们两个都应该放到B区域中,就这样你把所有的书籍都按这个规则整理好了。相比之前,现在想找一本书简直快的多了,比如我想要看《三体》,直接找到书桌上S标记的区域,然后在这区域叠起来的一摞书中找就是了!这个时候你太佩服自己了。
问题升级
时间久了你又遇到一个问题了:B区域的书太多了。我找一本首字母为B开头的书还是需要费很大力气呀,能不能对这里稍微再改进呢?
最终方案

咦,这个东西不错呀,把某个区域过多的书用这个代替,在这个书架中你可以再设定自己的一套规则(比如中文放左边,外文放右边),方便更快速的找书。当然你不会每个区域都买个小书架,这样成本太高了,所以你决定每当某个区域的书本多于N的时候(N由你自己决定),你就放一个小书架到这个区域里面。

经过上面的小故事,你知道HashMap的原理了吗?
HashMap 结构图
jdk1.7结构图
如果仔细读了上面的小故事,我想HashMap的原理大概已经知道了,现在我们来看下HashMap1.7的结构图
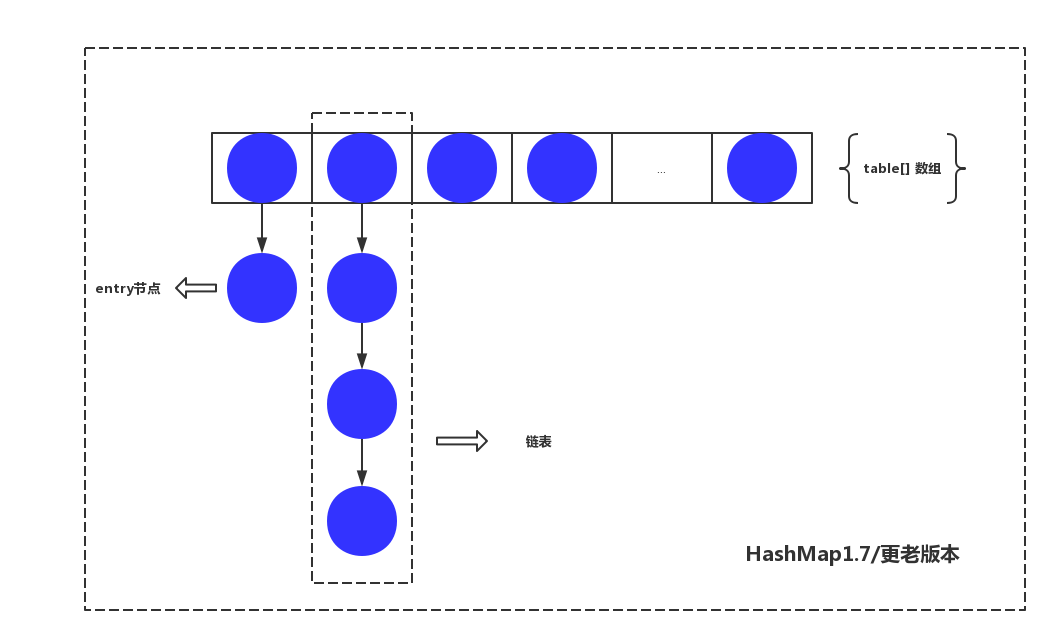
看到这个图是不是和上文中的书桌与书本极其相识?这里的table[]数组表示书桌,数组的每一个元素代表书桌的标记字母的区域,而entry节点表示书本。HashMap不断的存取数据(put方法)其实就是不断的向书桌增加书本。在HashMap里面有个概念叫Hash冲突,就是类似不同书本的首字母可能会相同,在书桌上我们采用一本本的叠加起来解决问题,相当于上图当中的链表。
jdk1.8结构图
在上面的故事中已经提到了,当书桌某个区域中的书越来越多的时候,我们在里面加了个小书架,因此在HashMap1.8中同样为了优化区域中搜索而引入了红黑树,来看下HashMap1.8的结构图
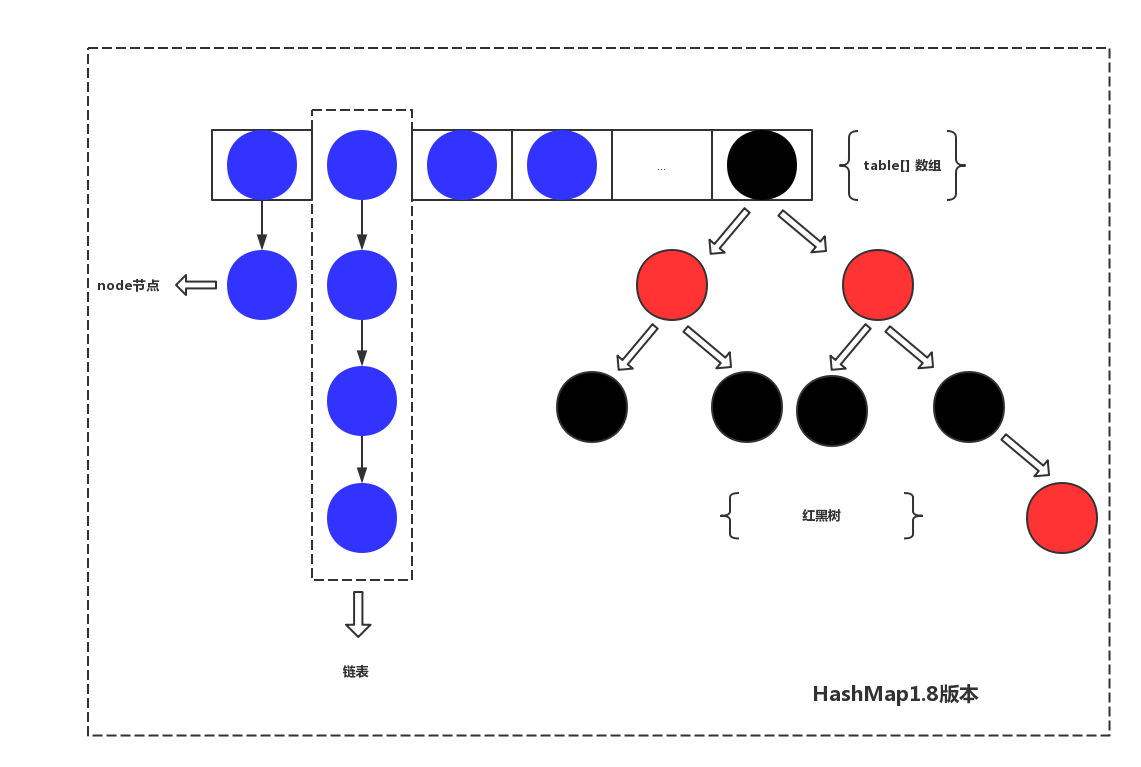
在HashMap1.8中引入了红黑树,能在链表长度过多的时候,增加查询速度。这就跟上面书桌区域中引入一个书架是一个道理,由于书太多,一本本的查询还是会花比较多的时间,针对区域进行优化,可以更快速的找到想要的书。
好了,说了这么多,是时候进入主题了。
HashMap 源码解析
关键变量
在HashMap源码中有几个关键变量,我们必须知道,通过这些变量我们可以更容易理解它的底层原理,注意这里的源码是基于1.8版本的
1 | /** |
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;默认起始容量,就是table数组的默认长度(2的4次方),相当于书桌上的区域数量,必须为2的N次方(为什么?后面解释)。
static final int MAXIMUM_CAPACITY = 1 << 30;最大容量,table数组的长度不能超过这个(2的30次方),即使超过也不会再改变。
static final float DEFAULT_LOAD_FACTOR = 0.75f;加载因子,这个干嘛的呢?我们知道table是一个数组,初始化的时候都必须指定一个长度,随着HashMap不断的put东西进去,这个数组需要扩容也就是增加长度。这个时候就是根据这个加载因子来扩容的,初始化的时候为16,当数组中的元素数量达到16*0.75=12的时候,table长度会变成原来的两倍。
static final int TREEIFY_THRESHOLD = 8;链表转红黑树阈值,当链表数量超过这个数的时候,它会将链表转为红黑树(这里并不打算讲红黑树的特性,具体百度,严格来说还有一个因素会影响是否转化成红黑树MIN_TREEIFY_CAPACITY,具体往下看)。
static final int UNTREEIFY_THRESHOLD = 6;红黑树转链表阈值,当红黑树数量小于这个数的时候,它会将红黑树转变为链表。
static final int MIN_TREEIFY_CAPACITY = 64;这个也是链表转为红黑树的一个条件,前面提到的一个条件是链表中的个数要大于8。而这里则是table数组的长度需要超过64,也就是说只有两个条件达到才会由链表转化为红黑树。
关键类与方法
hash()方法
hash方法对应将书本名称换算成字母的一个方法,如hash(“安徒生童话”) = A,贴上源码1
2
3
4static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
该方法能将一个key转换成int型的值。需要注意的是不同的key经过hash方法得到的值有可能是相同的,这就是所谓的hash冲突,前面也提到了,解决hash冲突主要采用的是拉链式的链表结构。从代码上我们也可以知道,当key为null的时候,统一规定hash返回为0,也就是说key为null的键值对会被放在table[0]这个区域里面(类似书桌第一块区域)。
Node类
Node是HashMap中的一个内部类,充当书桌上的书这一角色,组成链表的关键,先来看源码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
用通俗的话来说明上面的具体参数,hash指书名经过规则换算成A字母,key值书本名称,value指具体的书,next盖在当前书上书籍,形成拉链式的结构。
put(K key, V value)方法
看了源码的话我们会发现,在HashMap中的put方法实际上是调用了另外一个方法putVal。1
2
3public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
因此我们接下来看putVal这个方法,每行都补充了相关注释1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//将table赋值给tab,如果table为空或者长度为0,则调用resize()初始化,再把长度赋值给n
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//这里(n - 1) & hash相当于hash%(n-1),判断tab[i]这个区域是否已经有值,如果没有,则新建一个节点,并且赋值给p,把节点放到这个区域
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//如果tab[i]里面已经存在值了
else {
Node<K,V> e; K k;
//如果p这个节点的传进来的是一样的,则把p赋值给e
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果p为树类型节点,则调用树的putTreeVal方法,此方法就是一个红黑树添加
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//遍历区域中所有节点
else {
for (int binCount = 0; ; ++binCount) {
//将p的子节点赋值给e,如果区域中没有相同key的节点则直接插入到区域中(可能是链表可能是红黑树,具体查看treeifyBin方法),退出循环
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//如果区域中有相同key的节点直接退出循环,
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
//以上都没有,则e赋值给p继续循环
p = e;
}
}
//e不为空,说明之前区域中存在key与现在新的key相同,这时候将新值覆盖原来的旧值,并且返回旧值
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
另外再附上一张put方法完整流程图(点击可看大图)

get(Object key)方法
同样,从源码中可以看到主要是调用了getNode这个方法
1 | public V get(Object key) { |
下面贴上getNode的源码,里面也添加了相关注释1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//判断table是否为空并且长度不为0,根据hash得到应该存放的区域,区域头节点也不为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//是否与头结点的key相同,相同则直接返回该节点
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//头结点不匹配则进入遍历
if ((e = first.next) != null) {
//如果是树节点,遍历红黑树,找到节点立即返回该节点,具体红黑树的遍历查询需要查看getTreeNode方法
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//否则遍历链表,找到节点立即返回该节点
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
//没有找到对应的key,说明不存在,返回null;
return null;
}
总结
源码分析并不难,需要一颗平静的心,切勿浮躁。每个人的理解都不一样,选择自己的方式,效果会更明显。另外就是不能被一些专业的术语所吓到,很多所谓的术语其实很简单。